
先日、Kaggleを始めた初老SEが、タイタニックチュートリアル、Intro、Intermediateと学習を進めて来ました。
今回は、Intro、Intermediateで学習したことを復習しながら、タイタニックコンペに適用してモデルの改善を行ってみたいと思います。
なお、記事内容には勘違いしている点もあり得るかと思います。お気づきの際はご指摘いただければ幸いです。
まずはチュートリアルのおさらい
チュートリアルは以下の記事で書きました。

チュートリアルでは、RandomForestClasssifierを用いてモデルを構築しました。
モデル構築時のパラメータは、n_estimators=5, max_depth=5でした。
モデルのトレーニングに使用したデータは、[“Pclass”, “Sex”, “SibSp”, “Parch”]の4項目でした。
推論結果のスコアは、0.77511でした。
最初のアプローチ
今回は、Intro、Intermediateと学んできたことを活かし、チュートリアルのスコア0.77511を上回るスコアを目指します。
まずは最初のアプローチとして、「モデルのパラメータを変えてみる」「使用するモデルを変えてみる」「使用するデータ項目を増やしてみる」を試してみたいと思います。
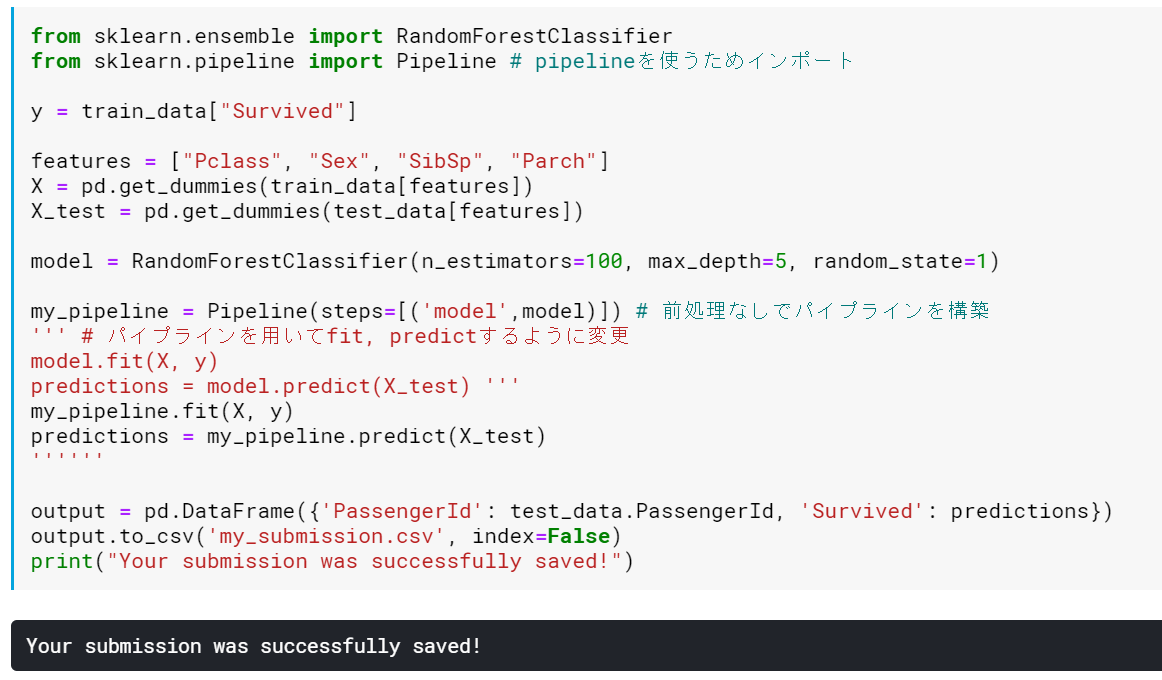
Pipelineを用いるようにする
Pipelineを用いるほどのことはしないかもしれませんが、癖付のためにもPipelineを用いるように変更してみます。Pipelineの作り方としては、「前処理の定義」「モデルの定義」「パイプラインの構成」の流れとなります。
チュートリアルのままを実現するため、ここでは、前処理は無し、モデルはRandomForestClasssifierをそのまま用いることになります。
具体的には、Pipelineをインポートして、Pipelineを構築、モデルで直接Fit/Predictするのではなく、このPipelineを用いてFit/Predictするように変更しました。
念のため推論結果をSubmitしてチュートリアルと同じスコアになることを確認しました。
モデルを評価できるようにする
今後のステップでモデルが改善しているかを評価するために、今あるデータをトレーニング用のデータと、評価用のデータに分割してやります。これには、sklearn.model_selection.train_test_splitを用いることになります。
また、Courseで学習した際には、Regressionモデル(回帰モデル)を用いての推論だったため、評価指標としてMean Absolute Errorを用いていましたが、今回は、Classificationになるため、評価指標としては、(最適かどうかは置いといて)Accuracyを用いることとし、sklearn.metrics.accuracy_scoreをインポートして、これを使うことにしてみます。
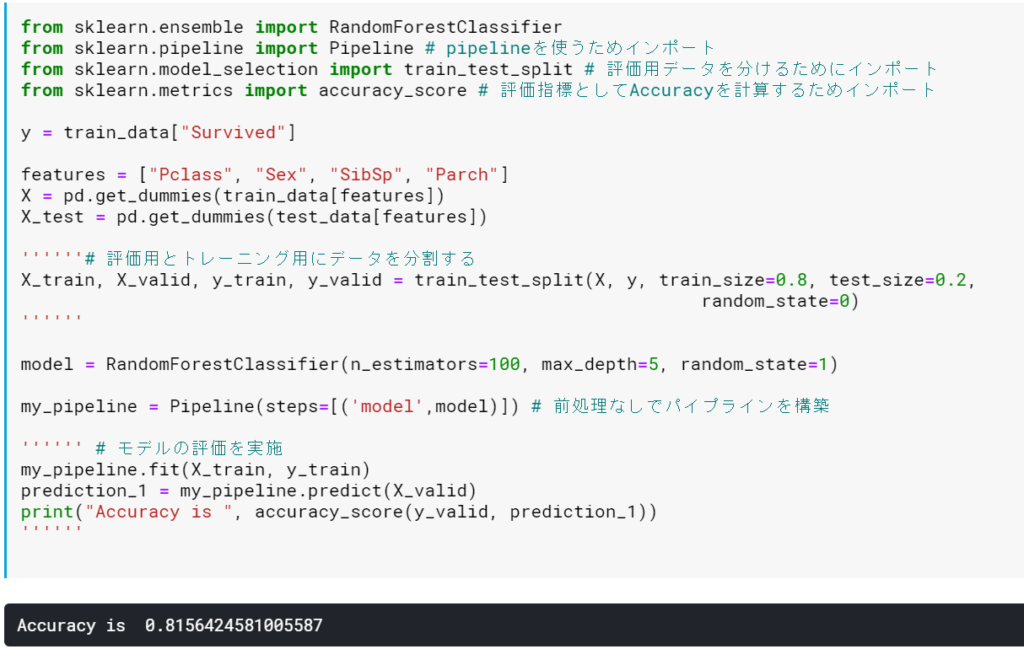
これで、モデルの評価ができるようになりました。
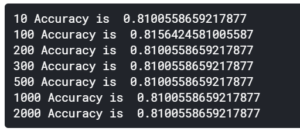
まずは単純にモデルのパラメータをいじってみる
まずは、単純にモデルのパラメータだけをいじってみて、どう変わるか確認したいと思います。
For文で複数のn_estimatorsの値を変更していき、それぞれのAccuracyを確認しました。

次いで、max_depthを変えていってみます。3~10の深さで試してみました。

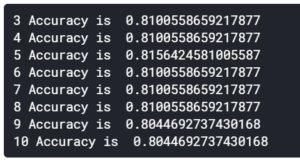
結果としては、チュートリアルで使用していた n_estimators=100, max_depth=5が(Accuracyを評価指標とした場合)最良のようでした。
使用するモデルを変えてみる
チュートリアルでは、RandomForestClasssifierを使用していましたが、ここでは、Intermediate Machine Learningで学んだ、XGBoostを使ってみようと思います。XGBoostにはXGBClassifierというのがあるようなので、こちらを使います。

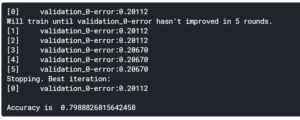
結果、Accuracyは下がってしまいました。。念のため、このモデルを使って推論結果をSubmitしてみまたところ、Scoreは0.77033と少し下がってしまいました。
使用するデータ項目を増やしてみる
まずは、既存のデータを見てみます。
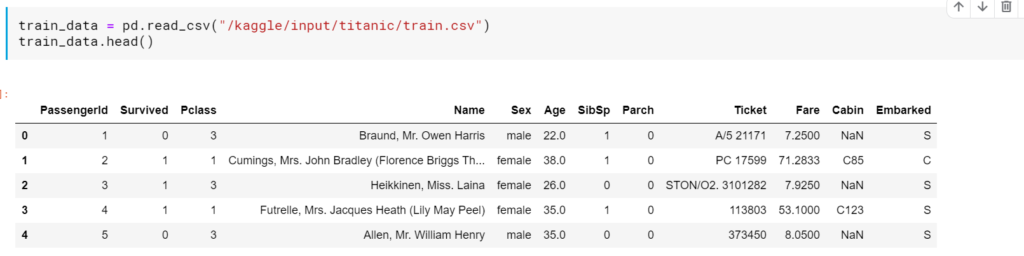
現在使っているデータ項目はPclass, Sex, SibSp, Parchの4項目です。他の項目で生死を分けそうな要素を検討します。各項目については、コンペのデータタブにて確認でき、以下を表しているようです。
- Name: 乗船者の名前
- Age: 乗船者の年齢
- Ticket: チケットの番号
- Fare: 運賃
- Cabin: キャビン番号
- Embarked: 乗船した港
この中で生死を分けそうなものとしてAgeを取り上げてみます。
データの情報を見てみます。AgeのCountが他のCountより少なくなっています。よって、Age列にはMissing value(欠損値)があると考えられるため、適切に前処理をしてやる必要がありそうです。
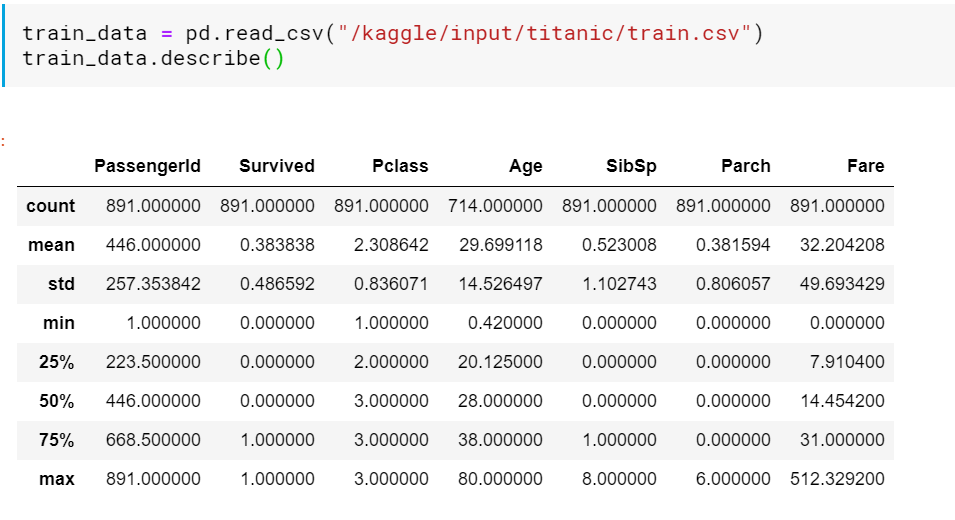
Age列の欠損値の扱いを決定する
Missing Valuesの扱い方としては、以下の選択肢がありました。
- Missing Valueを含む列ごと削除してしまう
- 他の値を参考に、データを補完(代入)する
- データを補完するとともに、補完の有無を追加する
今回は敢えてこの列を追加するので、1の選択肢はありえませんでしたので、比較的シンプルな2の方法で検討します。
Courseで学んだSimpleImputerを使用して代入することとしますが、どのようなルールで代入するかを検討します。SimpleImputerで使用できる代入方法としては下記のものがあるようです。
- mean: 平均値を代入する
- median: 中央値を代入する
- most_frequent: 最頻値を代入する
- constant: 定数を代入する
欠損値の扱いを定義する
まずは、SimpleImputerをインポートしStrategy=’mean’でPipelineに登録し、実行してみます。
これで、SimpleImputerでAge列の欠損値を平均値で埋めてモデル構築できていると思います。


Strategy=’mean’での結果、Accuracyは0.83240でした。他のStrategyでも試してみましたがmeanが最もよさそうです。

Submitする
以上の内容を踏まえ、モデルはチュートリアルのままで、FeaturesとしてAgeを追加、AgeのMissing valueはSimpleImputerで平均値を代入してやることでAccuracyは改善しました。
この状態で、Submitしてスコアを見てみようと思います。
この結果のスコアは、

0.77272ということで、チュートリアルの結果(0.77511)よりも悪化する結果となってしまいました。
まとめ
結果として、より良いスコアを取ることができなかったですね。そんな簡単に精度が上がらないものなのか、使い方が間違っているだけなのか、、、引き続き、改善に向けて他の方のNotebookなどを参考にして学習していきたいと思います。

