
さて、基礎となりそうなIntoro系のCoursesを受講してはみましたが、まだまだコンペに参加できる気がしません。そこで、Titanicコンペで0.85くらいのScoreを上げているNoteを拝見してみました。
いろいろなやり方をされていますが、よく目につくのは、特徴量をごにょごにょしている感じです。生データをそのまま使うのではなく、生死に影響を与えていそうな特徴量を見つけ出し、機械学習で扱えるようにしていくのが肝のようです。
つまりは、どのようなデータが結果に影響しているかを推測し、適切に前処理をしたうえで機械学習をさせているようです。まさに、Garbage in, garbage outということでしょうか。
というわけで、与えられたデータからどのデータが結果に影響を与えているかを見える化してやる必要性が出てきたので、kaggle courseで用意されているData Visualizationを受けてみることにしました。
このCourseでは、SeabornというツールをPhthonで使用してデータの可視化する方法を学びます。
Hello, Seaborn
Setup the notebook
実行環境はKaggleで標準的に使用されるのJupiter notebookを想定しています。
まずは、必要なパッケージ類をインポートしてnotebookをセットアップします。
Load the data
今までのCourseでも学習したことですがPandasを用いてCSVファイルを読み取ります。

read_csvの引数として、今までのCourseでは出ていなかったindex_col, parse_dateというものが出てきています。
index_colでは、インデックスとして今後使用する列を指定しているようです。またparse_dateでは、データを、可能であれば日付型に変換することを指示しているようです。
Examine the data
では、きちんと取り込めたか確認します。headで最初の5レコードを表示することができます。
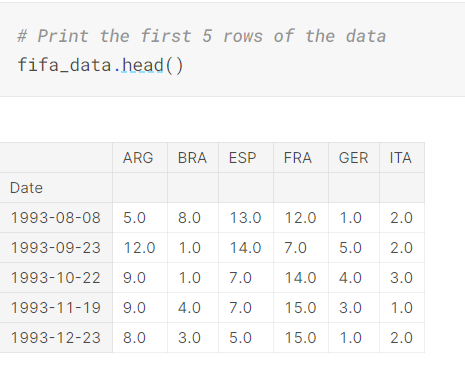
出力を見ると、Data列がきちんと日付の形に変換されていることが分かります。
Plot the data
いよいよ可視化の一歩、グラフ化してみます。

Exercise
以上をExerciseを通して体験します。ExerciseのStep1はExerciseの使い方になるのでスキップします。
このExerciseを通して、非常に簡単にグラフの描画ができることを学びました。
Line Charts
ここでは、音楽ストリーミングサービスであるSpotifyでのある楽曲の再生数データを折れ線グラフ化する方法を学びます。
先ほど学んだ方法で、notebookの設定、対象ファイルの読み込みを行います。

ファイルを読み込めば、lineplot関数にデータを渡してやるだけで線グラフを作成することができます。
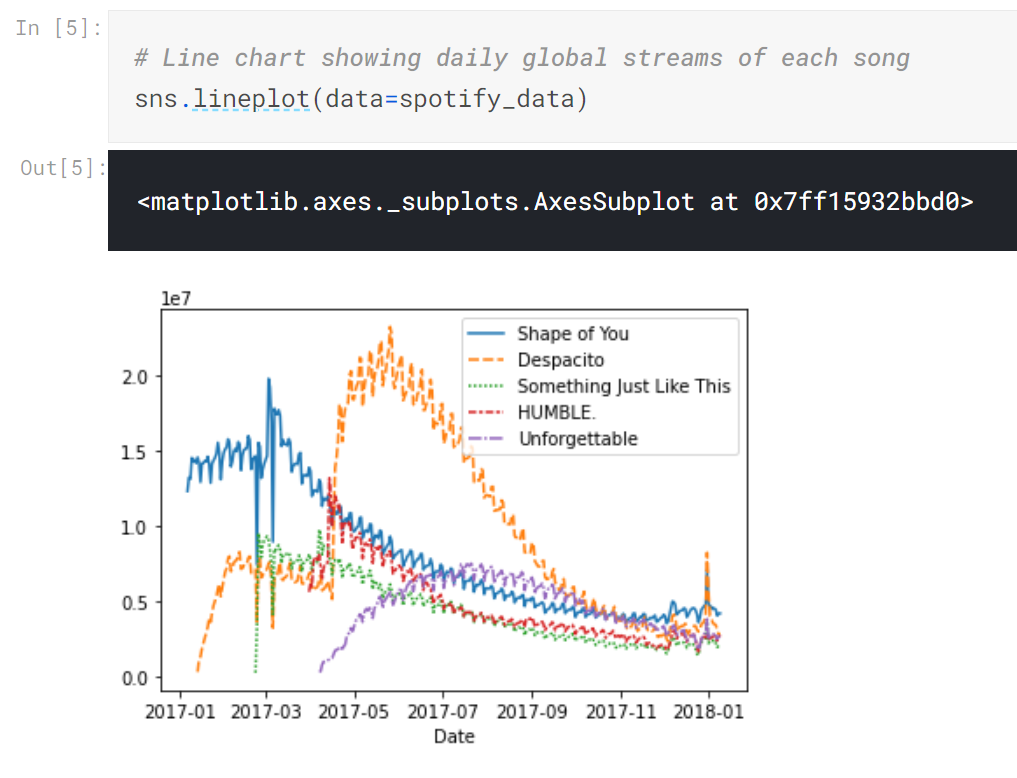
思った以上に簡単にグラフ化することができました。
また、title()で任意の文字列を指定すればグラフにタイトルをつけることもできます。
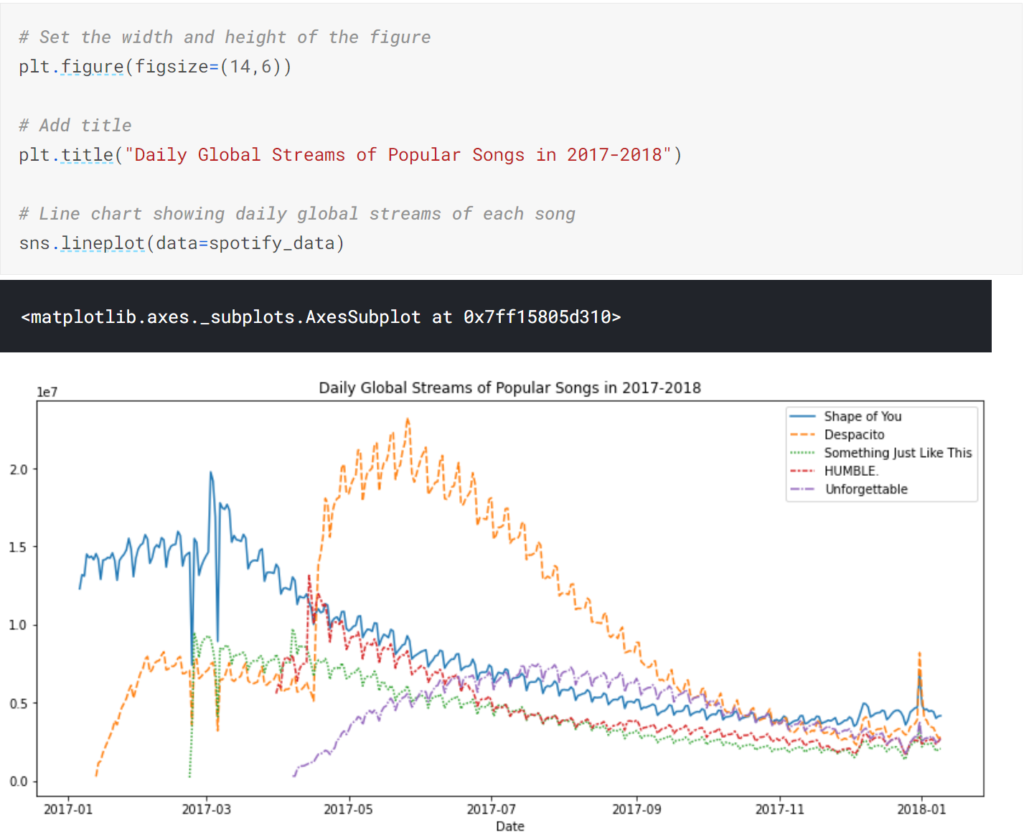
また、データ内の特定の属性値のみをグラフ化することもできます。
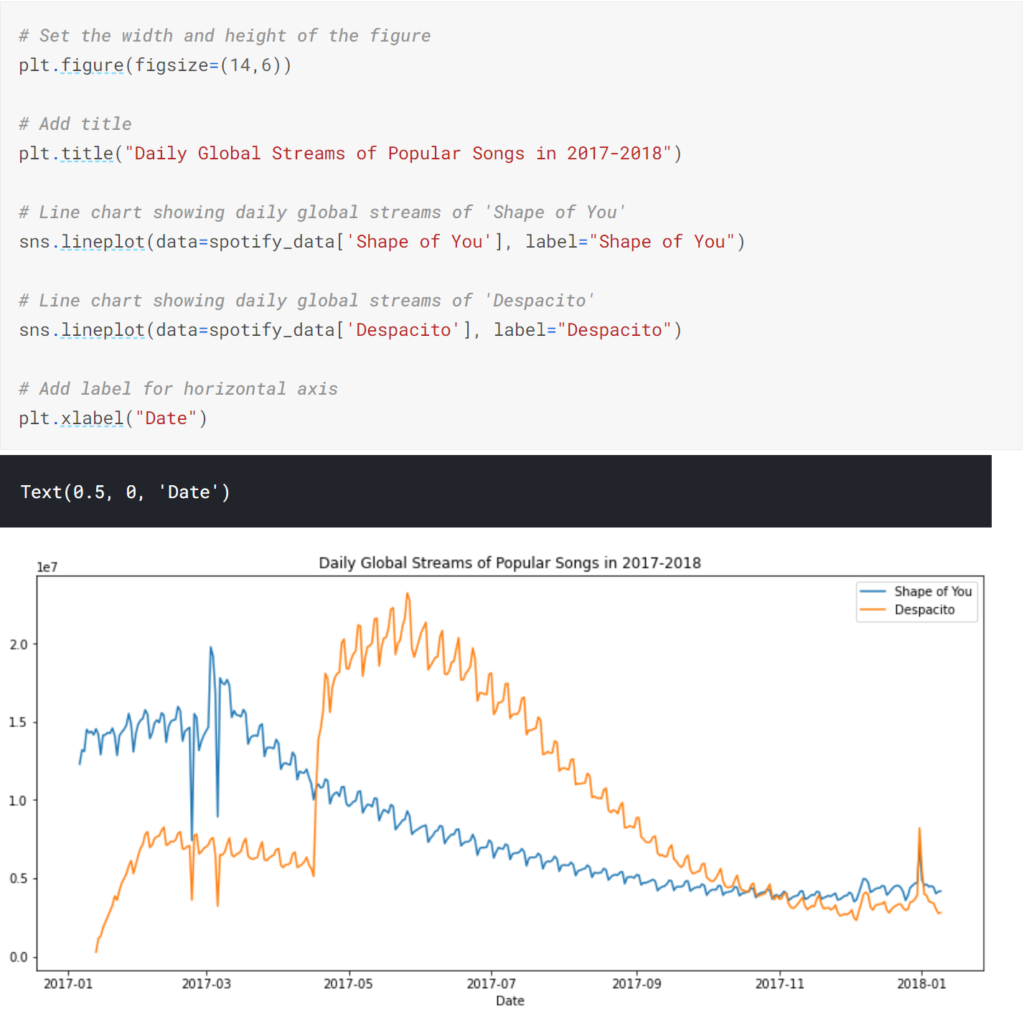
lineplotの引数dataに対象の属性のみの配列を渡すことで特定の属性値のみを表示することができます。lineplotの引数labelで描画対象のラベル名(凡例)を設定できます。
なお、最後のplt.xlabelでは、x軸の名前を付けています。
チュートリアルでは、ロサンゼルスの博物館の客数データを基にグラフ化を行う練習をします。
Bar Charts and Heatmaps
ここでは棒グラフとヒートマップの描画方法を学習します。以下のような棒グラフや、ヒートマップも1行のコマンドで描画することができます。
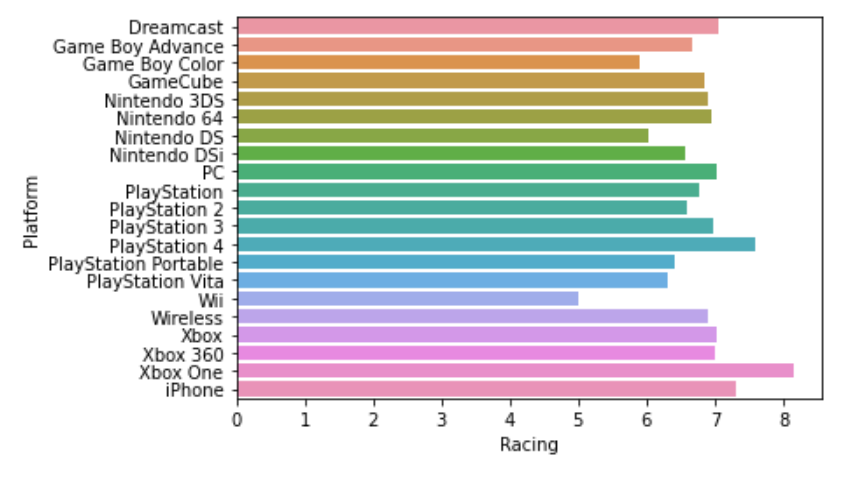
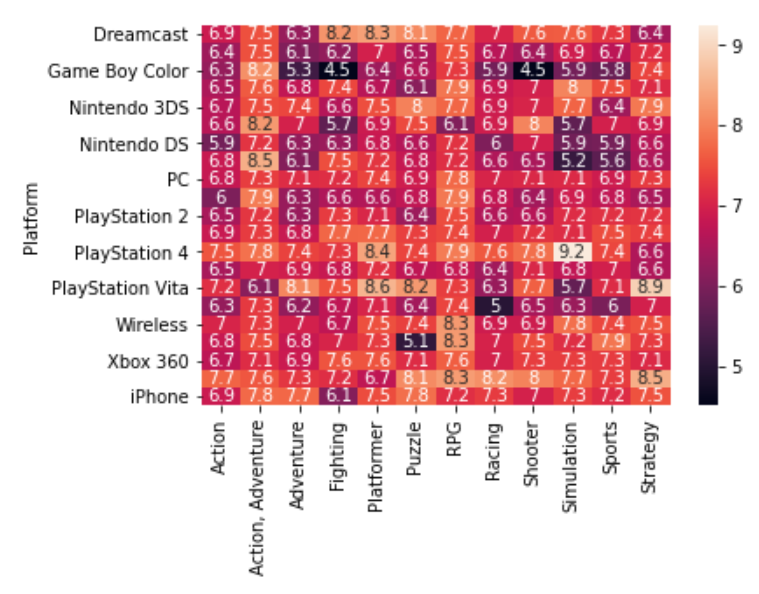
Bar Chart
棒グラフを描画するには、barplotを使用します。引数には、X軸に使う値とY軸に使う値をそれぞれx=, y=でしてします。
X軸、Y軸に使用する列を指定する必要がありますが、Indexにしている列(データ読み込み時にindex_colで指定している列)は列名での指定はできず、.indexとして指定する必要があります。
正:sns.barplot(x=data.index, y=data[‘NK’])
誤:sns.barplot(x=data[‘Month’], y=data[‘NK’])
Heatmap
ヒートマップを描画するには、heatmapを使用します。引数dataに対象となるデータを渡せばヒートマップが作れます。またヒートマップの中に値も表示させたければ、annot=Trueとします。
Scatter Plots
Scatter Plot(散布図)を描画するには、scatterplotを使用し、barplot同様、X軸、Y軸に使用する値を指定すれば描画できます。
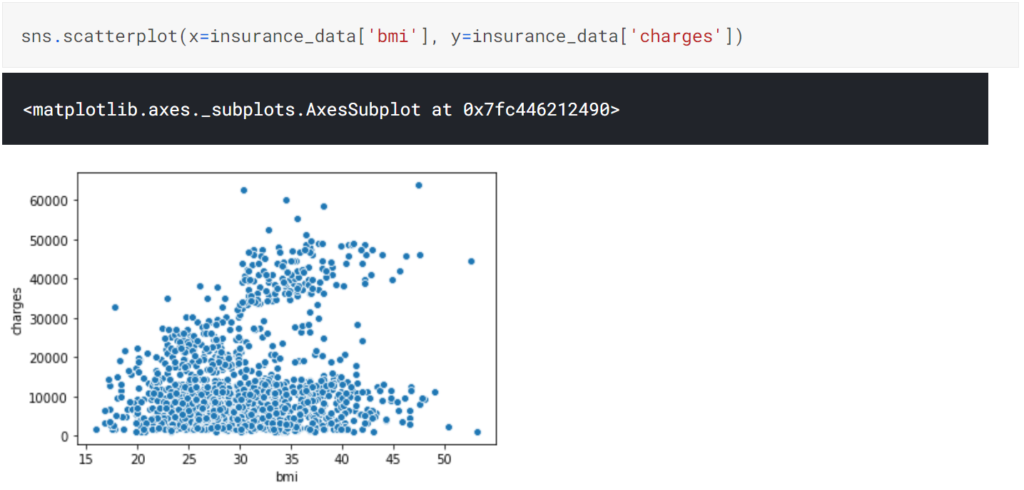
また、散布図のみでなく、その散布図上に回帰直線を追記したものをregplotを使用することで描画できます。
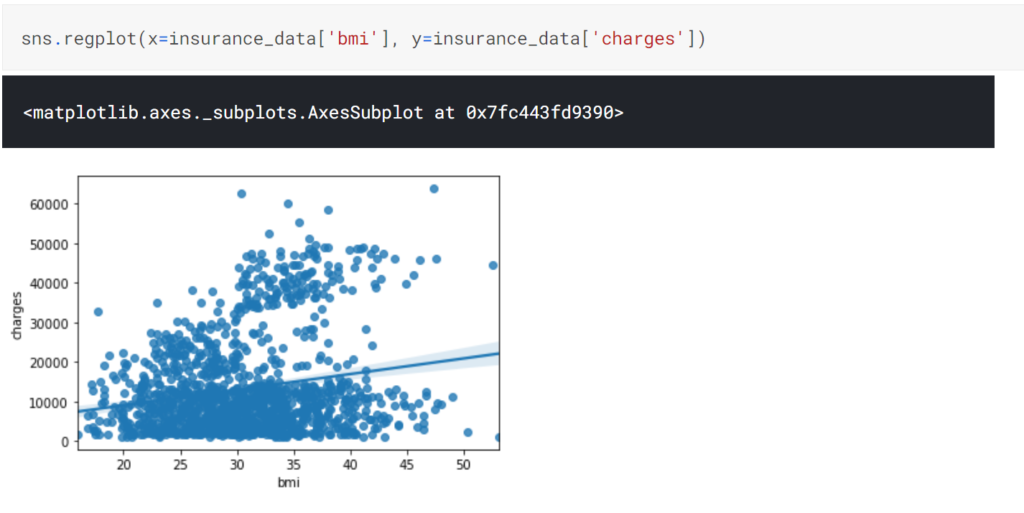
さらに、色相を追加することでもう1種類の情報を追加して描画することができます。
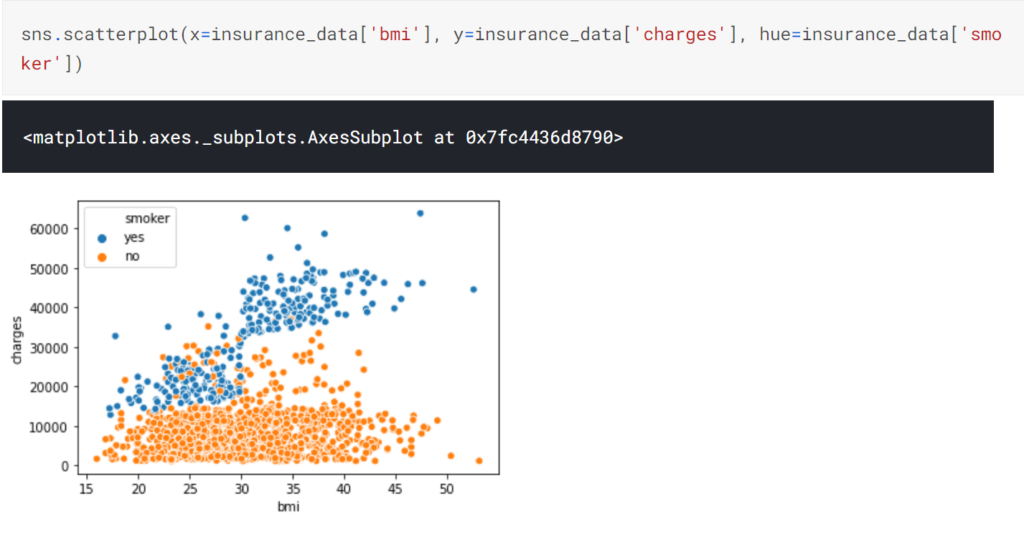
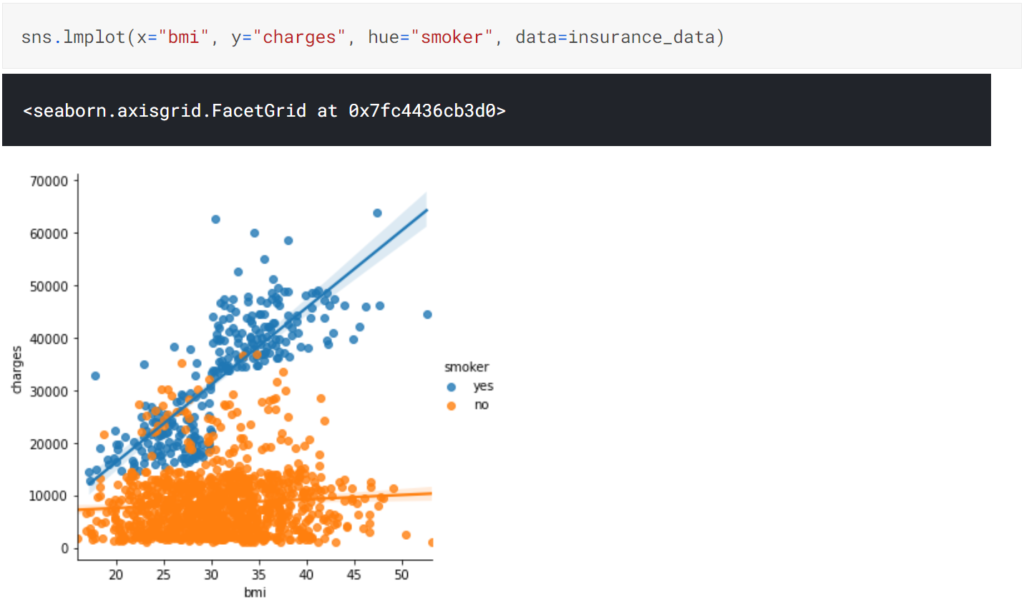
また、lmplotを用いることで、これらの色相に分けたデータ群ごとに回帰直線を追加することも可能です。ただ、lmplotの使い方は前述の関数とは少し異なります。
x,y軸の値や、色相Hueとして列名のみを指定することになります。
さらにもう一つの描画方法としてswarmplotがあります。
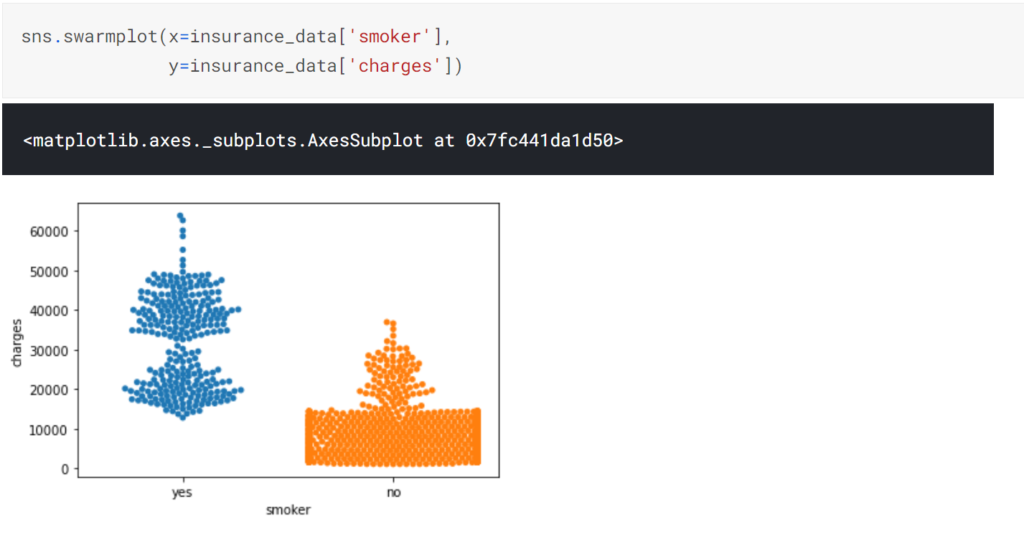
Distributions
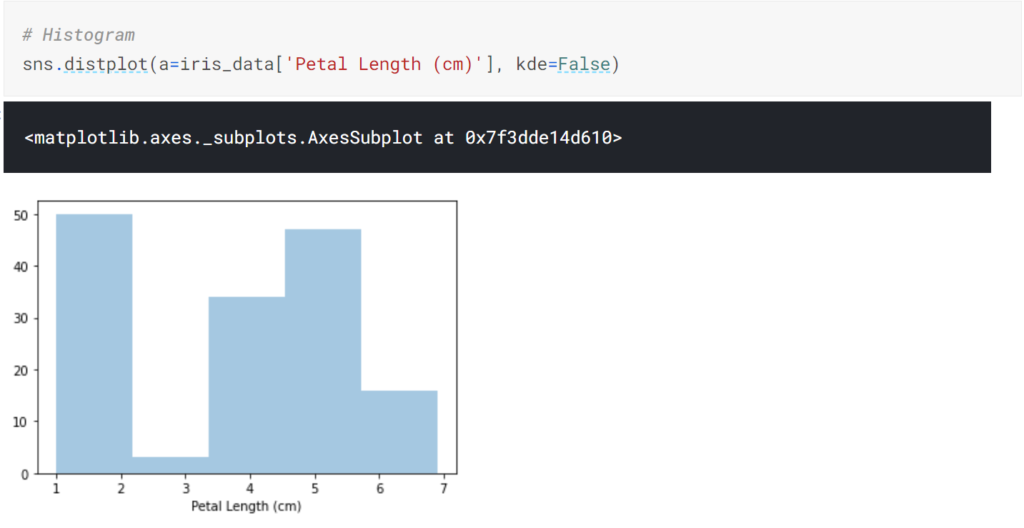
Histograms
基本的なヒストグラムを作成するには、distplotを使用します。引数のa=で対象となるデータを指定します。
Choosing Plot Types and Custom Styles
さて、ここでは今まで学んだグラフのスタイルをどういった使い分けをすべきかを学びます。ざっくりと以下の3パターンに分類できます。
傾向を見るなら、lineplot
関係性を見るなら、barplot, heatmap, scatterplot, regplot, lmplot, swarmplot
ばらつき具合を見るなら、displot, kdeplot, joinplot
このように目的に合わせてグラフを使い分けると良いようです。
Changing styles with seaborn
簡単なコードにもかかわらず、キレイな見栄えにグラフ化してくれるSeabornですが、さらに少し書き加えることで見栄えをカスタマイズできるようです。
具体的には、set_styleでスタイルを指定するだけで、使用できるスタイルには以下の5種類があります。
(1)”darkgrid”, (2)”whitegrid”, (3)”dark”, (4)”white”, (5)”ticks”,
Final Project
Final Projectおよび次のCreating Your Own Notebookでは、自身のPC上にあるファイルをNotebookにアップロードして、可視化する方法を学びました。特に難しいものでもなくNotebookのGUIから容易にアップロードが可能です。
以上で、データの可視化方法の学習は終了です。ここで学んだ手法を活用してデータの依存関係を推測し適切な特徴量エンジニアリングを行うことでAIの精度を上げていくようです。
次は、これらのデータにどのような処理を行いAIに使いやすくするのかをFeature EnginieeringのCourseで勉強していきたいと思います。

