
1
異なる音声データを比較する際にはDPマッチングや隠れマルコフモデル(HMM)などを用いた伸縮マッチング手法が広く用いられるが、こうした手法が必要な理由は、たとえ同一の単語でも発音ごとに各音素の長さは変化するため、1つの時間伸縮する枠組みの中で比較する必要があるから。
2
自己回帰モデル(ARモデル)による分析対象例として、(株価予測)が挙げられる。
3
個人情報の保護に関する法律(個人情報保護法)において以下の義務がある。
- 個人情報取扱事業者は、利用する必要がなくなったときは、個人データを遅延なく消去するよう努めなければならない。(努力義務)
- 個人情報取扱事業者は、その取り扱う個人データの安全管理のために必要かつ適切な措置を講じなければならない。
- 個人情報取扱事業者が従業者に個人データを取り扱わせるにあたっては、その個人データの安全管理が図られるよう、その従業者に対して必要かつ適切な監督をしなければならない。
- 個人情報取扱事業者は、個人データの取り扱いを委託する場合、取り扱いを委託された個人データの安全管理が図られるよう、委託を受けたものに対して必要かつ適切な監督をしなければならない。
4
発明者に関する説明。
- 特許法上、人工知能(AI)が発明者となることはない。
- 株式会社等の法人が発明者となることはない。
- 複数の者の共同作業によりプログラムを発明した場合、その全員が発明者となることができる。
- 発明者でなくても、特許出願することができる場合がある。
5
パラメータ更新にかかわる単位のうち、パラメータが更新された回数を示す語句は、(イテレーション)である。
6
ニューラルネットワーク構造の最適化のため、大量のGPUを用いて並列でネットワークの構造を探索することができる手法は(NAS (Neural Architecture Search))である。
7
双方向リカレントニューラルネットワークのにおいては、t=1からt=Txの走査に加えて、逆順の t=Txからt=1の走査も加える。なお、入力される系列データにおいて、t=1を最初の時刻、t=Txを最終の時刻とする。
8
情報量の情報の珍しさを示すと解釈できる。一般に任意の事象の生起確率を(対数)変換した値に-1をかけた形で表現される。この値は事象の生起確率が低ければ低いほど大きくなり、逆にほとんど確実に生起する場合には0に近づく。
9
コンピュータにとっては、知能テストやチェッカーをプレイさせたりするよりも、1歳児レベルの知恵と連動のスキルを与えるほうが遥かに難しいという(モラベックのパラドクス)が広く知られている。
10
学習率(learning rate)に関する説明。
- 一般に学習率の値が低すぎると収束するための時間が延びる。
- 学習率の値を適切な範囲で大きく設定することで学習が早く進む。
- 学習率の値を大きくしすぎると収束しない。
11
強化学習の学習手法の説明として、最も適切な選択肢を1つ選べ。
- 価値関数ベースの手法は、各状態の価値を算出し、値が最も高い状態に遷移する行動を取るというものである。
- 方策関数ベースの手法では、各試行の最終的な結果から方策を更新するため、行動の価値は分かるが状態の価値は計算できない。
- 価値関数ベース手法に価値反復法がある。これは環境ダイナミクスがわからないときに利用できる手法である。
- ディープQネットワーク(DQN)は方策関数ベースの手法の1つである。
12
早期終了(Early stopping)は機械学習や深層学習において過学習を避けるため、その名の通り学習を早期終了させるテクニックである。特に勾配ブースティングについては直前に学習させたモデルの予測誤差を修正していくように順次学習が行われるため、この技術を導入することが過学習を避けるために重要となる。早期終了では、モデルの学習が打ち切られた時のパラメータをモデルに採用する。
13
学習済みの大規模なモデルを教師モデルとして、小規模なモデルの学習に利用する手法を(蒸留(distillation))と呼び、モデル圧縮などに活用されている。
14
以下に挙げる手法は、強化学習で用いられる手法を指している。
- TD学習
- Q学習
- モンテカルロ法
15
図Aのように、学習を進めたときに途中から検証データのコスト関数の値のみが高いままになった状態が過学習と呼ばれる。
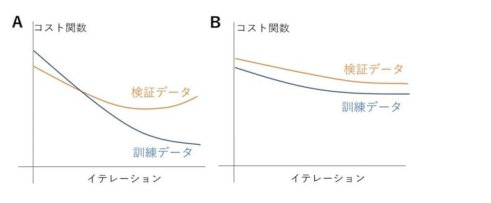
16
状態空間モデルに関する説明。
- ARIMAモデルなども状態空間モデルとして表現することが可能である。
- 状態方程式と観測方程式を用いてデータを表現する。
- パラメータ推定において、カルマンフィルタやマルコフ連鎖モンテカルロ法を用いて推定を行うことができる。
- 自己回帰モデルのARモデルやARIMAモデルより予測精度がよいことが理論的に保障されている。
17
ディープニューラルネットワーク(DNN)の順伝搬の計算において、前の層の出力に重みを乗算したのちに加算するものをバイアスと呼ぶ。
18
従来の機械学習で利用されていた最適化手法である最急降下法は、一度の学習にすべてのデータを利用することから(バッチ学習)と呼ばれている。しかし、ディープラーニングの場合データが大規模であることからそれが難しい。よって、確率的勾配降下法という手法が用いられることも多い。ひとつのサンプルが入るたびに学習に利用する手法は(オンライン学習)と呼ばれる。(バッチ学習)と(オンライン学習)は、どちらにも長所と短所があり、一定数のサンプル群を利用する(ミニバッチ学習)が採用されることが推奨される。
19
機械学習におけるデータ集合において、検証データは訓練データから切り出され、検証データを用いて評価された性能をもとにハイパーパラメータの調整を行う。
20
以下の文章を読み、空欄(A)~(C)に当てはまる用語の組み合わせとして最も適切な選択肢を1つ選べ。
ある画像a0をガウシアンフィルタで1/2のサイズに畳み込んだ画像をa1とする。a1に関しても同じ処理を施した画像をa2とし、以下同じ作業を繰り返して得られる画像群を(ガウシアンピラミッド)という。また、a1を2倍に拡大し、a0との差分として得られる画像をb0とする。以下同じ作業を繰り替ええして得られる画像群を(ラプラシアンピラミッド)という。(ラプラシアンピラミッド)の画像は処理を繰り返す毎に徐々に解像度が低くなっており、この構造は(CNN)に似ている。
