AI学習のために、思い立って登録したKaggleですが、Intro to Machine Learningを理解したつもりになったので、次のステップとしてIntermediate Machine LearningのCourseを受けてみることにしました。

このコースはIntroに比較して飛躍的に難しいと感じましたが、自身の理解を整理するためにもいかにまとめていきます。(間違いがあればご指摘いただければ幸いです)
Introduction
このIntermediate Machine Learningコースでは、以下のことを学ぶことができます。
- missing values(欠損値)、categorical variables(カテゴリ値)の取り扱い
- pipeline(パイプライン)の使い方を理解する
- モデルの評価手法の一つであるCross-validationを実行する
- XGBoostモデルの構築(最先端でKaggleでも好成績を出しているモデルらしい)
- Leakageについて理解する
この章のExerciseでは、ランダムフォレストのモデルをそれぞれ異なる条件(決定木の数や深さなど)で複数作成し、それぞれのスコア(ここではMAE)を求め、スコアをもとに最良のものを選択し予測を行いました。
Missing Values
Missing Values(欠損値あるいは欠測値)は、その名の通り、データとして取れていない値のこと。項目はあるが値が入っていない(0でもない)というもので、NullであったりN/Aとかで表現されるようなものと思えばよいと思う。多くのライブラリではMissing valuesを用いてモデル構築をするとエラーとなるらしく、正しく処理してやる必要があるとのこと。
基本的なMissing valuesの取り扱い方は以下の3種類
- Missing Valueを含む列ごと削除してしまう
- 他の値を参考に、データを補完(代入)する
- データを補完するとともに、補完の有無を追加する
1. Missing Valuesを含む列ごと削除する
これはイメージしやすいです。Missing Valueを含む列を列ごと削除してしまう方法です。
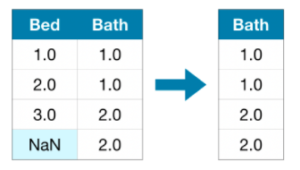
ただ、列ごと削除してしまう=特徴量を1つ失うこととなるので、この方法をとるかどうかはケースバイケースで判断が必要。Missing Valueが多い場合(ほとんどのレコードがその項目に値を持たない場合)は、この方法でよいらしい。
具体的には、pandas.DataFrame.drop()を使って不要列を削除することとなる。
2. 他の値を参考に、データを補完(代入)する
2つ目の方法は、Missing valueに対して、他の値を参考に、仮の値を代入する方法です。平均値や最頻値などの値を代入してやる方法で、一般的に、単純に列を削除するより精度がよさそう。
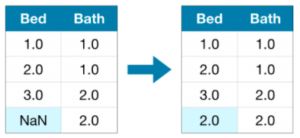
値を代入するには、sklearn.Impute.SimpleImputerを用いる。SimpleImputerでは、fit()によりデータの中身を確認して、代入式を決定、transform()により決められた代入式による代入を行う様子。トレーニングデータに対してfitを行い代入式を決定後、同じ代入式でトレーニングデータ、評価用データの代入を行うことになる。(そのため、トレーニングデータに対してはfit()とtransform()を連続して行うfit_transform()が用いられ、評価用データにはtransform()のみ実行していると思われる)
3. データを補完するとともに、補完の有無を追加する
この方法は、2と同じように代入するとともに、値が補完されたことを区別するための列を追加する方法となります。
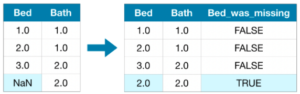
この方法は、2の方法同様に、SimpleImputerを用いて値を代入した後、for文で補完した列情報を追加していくことで実現しました。
この章のExerciseでは、列ごと削除してしまうケースと、Imputerを用いて値を代入した場合でのスコア(MAE)の違いを確認しました。
列ごと削除した場合のMAEは 17837.82570776256 、SimpleImputerを用いた場合 18062.894611872147 となり、列ごと削除してしまったほうが、よい結果を得ることができました。これは、SimpleImputerでの代入式(Defaultなのでmean:平均値を代入した)が妥当でなかったことなどが考えられます。実際、このExercise内でも、SimpleImputer(strategy=’median’)として、中央値を代入するようにすると、17791.59899543379となり、最もよい結果となりました。
ここで、Imputerを用いて代入した場合、DataFrameからは列名(Column name)が削除されてしまうようで、それらを戻すために、imputed_X_train.columns = X_train.columns により元のDataFrameのcolumnsを設定しなおす必要があるようです。
Categorical Values
Categorical variables(カテゴリ値)は、値がカテゴリーで表示されるもののこと。例えば、[“好き”, “どちらかといえば好き”, “どちらかといえば嫌い”, “嫌い”]であったり、[“Honda”, “Toyota”, “Subaru”, “MAZDA”, “OTHER”]など数値ではあらわされないものをいう。このようなデータもモデル構築時のエラーになるため、適切に処理してやる必要がある。
この処理方法も以下の3パターンとなる。
- Categorical variablesを含む列を削除する
- ラベルエンコーディングを行う
- One-Hotエンコーディングを行う
1. Categorical variablesを含む列を削除する
Categorical variablesを含む列を削除してしまう方法。項目を列ごと削除してしまう=特徴量を1つ失うことになるので、持つ情報によって適切に判断する必要がある。
具体的な方法としては、pandas.DataFrame.select_dtypes(exclude=[‘object’])を用いることで、object型の値(String値)を持つ列を除外した(=object型の値を持つ列を削除した)DataFrameを得ることができる。
2. ラベルエンコーディングを行う
Label encodingにより、Categorical variablesを数値に変換する方法。
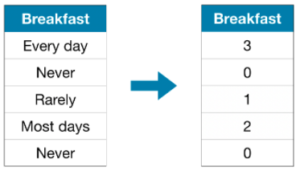
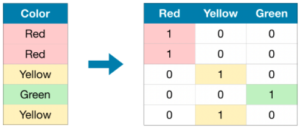
上図の例のように、各カテゴリ値に順序がある場合(この例では、頻度が高いほうが数値も大きい)、木構造のモデルでは特に有用とのこと。
具体的には、LabelEncoderを用いて、fit()により返還式を決定, transform()により変換することとなる。
3. One-Hotエンコーディングを行う
One-Hotエンコーディングでは、各カテゴリ値ごとに列を追加し、その列の値に0または1を埋めて表現する方法。各カテゴリ値に順序がない場合によく用いられる。カテゴリ値としての選択肢が多くなる場合、列数が増えることになるため用いないほうが良い(ここでは15種類以上の選択肢がある場合は使うべきではないとされている)
One-Hotエンコーディングの方法も、OneHotEncoderを用いて、fit, transformを実行し変換することになります。ただ、One-Hotエンコーディングでは、列の中身を変換するだけでなく、表の形も(列を追加することになるので)変化するので、他の方法と比べて手順が煩雑になりました。
流れとしては、以下のような作業が必要となるようです。
- カテゴリ値を持つ列を抽出
- カテゴリ値を持つ列をOneHotEncoderでfit, transform
- 訓練データ、評価データからカテゴリ値を持つ列を削除
- 3のデータに2で作ったデータを連結
一般的には、One-Hotエンコーディングが最もよいパフォーマンスを発揮するとのことですが、結局のところ、データの内容によって適切なものを使い分ける必要があるとのこと。
この章のExerciseでは、Categorical variablesを持つ列を削除するケース、ラベルエンコードを実施したケース、One-Hotエンコーディングを実施したケースでのMAEを比較しました。このExerciseでは、One-Hotエンコーディングが最もMAEが小さく、ラベルエンコーディング、列削除でMAEが悪くなっていきました。
Pipelines
Pipeline(パイプライン)は、データの前処理とモデリングをひとまとめにするもののようです。Pipelineを用いるメリットとしては以下のようなことがあり、使用が推奨されているようです。
- コードが簡潔になる
- バグを低減できる
- 本番化する際の手順が容易になる
- 様々なモデル評価手法を活用できる
Pipelineの構築手順は以下の通り
- データ前処理手順を定義する
- 使用するモデルを定義する
- Pipelineの作成と評価
1. データ前処理手順を定義する
Pipelineでは、前処理をListの形式で列挙することでひとまとめにすることができる。
2. 使用するモデルを定義する
今までと同様の方法で、モデルを定義する。ここでは、RandomForestRegressorを定義しました。
3. Pipelineの作成と評価
最後に、以下のように、1で定義した前処理preprocessorと、2で定義したモデルmodelをstepsとして登録することで、一連の流れをPipelineにまとめることになります。
Pipeline(steps=[(‘preprocessor’, preprocessor),(‘model’, model)])
このPipelineを用いて、訓練データに対してfit()を実行し、評価用データにpredict()を実行することで、前処理とモデル化、推論の実行が実現できます。
この章のExerciseでは、まず、前処理として、「数値の列のMissing valuesにSimpleImputerにて定数を代入」、「Categorical variables列のMissing valuesにSimpleImputerにて最頻値を代入」、「Categorical variables列をOne-Hotエンコーディングにより変換」することを定義します。モデルには、RandomForestRegressorを使用することとしPipelineを構成しました。
また、構成したPipelineを用いて、fit(), predict()を行い、Pipelineを活用した前処理、推論の実行の方法を学習しました。
Cross-Validation
ここでは、モデルの評価手法としてCross-Validationについて学習しました。Cross-Validationでは、データを複数のFoldに分割し、1つを評価用データとして、残りを訓練用データとして活用する方法です。例えば、5つのFoldに分割(Fold a~e)し、Fold b~eを用いてモデルを訓練し、Fold a で評価する。次いで、Fold a, c~eを用いてモデルを訓練し、Fold bを用いて評価する。という流れを繰り返すことで、訓練データ、評価用データの偏りによる評価の偏りを抑制できます。
繰り返しの処理となるため、計算量が多くなりがちなので、利用できるデータが少ない場合などに有用とされています。データが少ない/多いの明確な指標はないものの、モデル実行に数分程度で済むようであれば、Cross-Validationを行ったほうが良いとされています。
実際にCross-Validationを行うにはpipelineを用いない場合、非常に複雑なコードとなります。Pipelineを用いることで比較的簡単にCross-validationを行えます。Cross-Validationを実行するには、sklearn.model_selection.cross_val_score()を用います。これにより、任意のFoldに分割し、それぞれの組み合わせでのScoreを得ることができ、データの偏りによる影響が少ないモデルの評価をすることができます(ここでは5つのFoldに分割し、それぞれの平均値をとり評価している)。
この章のExerciseでは、数値データの列のみを用いて、RandomForestRegressorのn_estimator値を変更することで精度がどのように変化するかをCross-Validationを用いて評価しながらかくにんました。
XGBoost
ここでは、扱いやすくKaggleコンペでもよく使われているというXGBoostの使い方を学習しました。XGBoostはアンサンブル学習を用いた手法の一つでgradient boosting(勾配ブースティング)により精度を高めています(詳細は良く分かってません)。
ここでは、XGBoostのパラメータについて学習しました。
- n_estimators:
- モデル構築・評価のサイクルを繰り返す最大値をセット。100~1000あたりとのこと。
- early_stop_rounds:
- アーリーストップするまでの回数。評価結果が改善しないケースがこの回数だけ続くとn_estimatorsで定義した回数に達していなくても終了する。early_stop_rounds=5あたりを推奨している様子。
- learning_rate:
- 学習率を決定します。
- n_jobs:
- 並行して処理する数を設定します。少ないデータセットではあまり影響しないが、一般的にマシンのコア数と同じにすることが推奨されています。
この章のExerciseでは、まず、単純にXGBoostを用いたモデルを構築した後、パラメータを調整することでモデルを改善する方法を学びました。また、逆にパラメータの設定によっては精度が悪化することも学びました。
Data Leakage
ここでは、Data Leakageについて学びました。”リーケージ”という言葉から、「漏れ出る」という印象でしたが、この章で学ぶことで、どちらかというと「染み込む」とう意味合いなのだと理解しました。(モデルのトレーニングに使うべきでない情報が、トレーニングデータに染み込んできてしまう)
この章のExerciseでは、複数のケースのデータを見て、どの項目をトレーニングに含むべきではないか?(どの項目を入れるとLeakageを引き起こしてしまい得るか)を考えることでLeakageについての理解を深めました。
まとめ
以上で、Intermediate Machine LearningのCourseは終了となります。この後はいろいろなコンペに参加してみろということのようです。
Intro to Deep Learningを受けたいところなのですが、まずは今まで学習したことの復習を兼ねて、最初に実施したタイタニック号のコンペを、今まで学習したことを活用して改善していきたいと思います。

